
(cross posted from here)
In this post I’m going to talk about three types of uncertainty, and how the foundations of cryptography can be understood in their terms. Wikpedia says
Uncertainty is the situation which involves imperfect and / or unknown information. It applies to predictions of future events, to physical measurements that are already made, or to the unknown.
Two main concepts to note here, information and knowledge. We could say that uncertainty is lack of knowledge or lack of information. As we’ll see these two ideas are not equivalent and do not cover all cases. We start at the strongest form of uncertainty.
Ontological uncertainty: indeterminacy
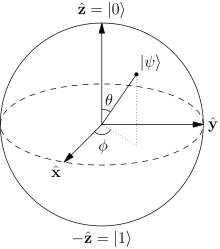
The Bloch sphere representing the state of a spin 1/2 particle.
In quantum mechanics, certain particles (spin 1/2 particles such as electrons) have a property called spin that when measured[1] can give two discrete results, call them “spin up” and “spin down”. This is described by the equation
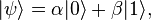
such that when measured, the probability of obtaining spin up is α², and spin down is β². A question we could ask ourselves is, before we measure it, is the spin up or is it down? But the equation above only gives us probabilities of what will happen when we make the measurement.
In mainstream interpretations of quantum mechanics there is no fact of the matter as to what the value of the spin was before we made the measurement. And there is no fact of the matter as to what the measurement will yield prior to it happening. The information that our question is asking for simply does not exist in the universe.
It is this intrinsic indeterminacy that makes us use the term ontological uncertainty: the uncertainty is not a property of our knowledge, but a property of nature. Our confusion is a consequence of the ontological mismatch between nature and our model of it. We sum up this type of uncertainty as:
The information does not exist and therefore we cannot know it.
By the way, the heisenberg uncertainty principle which is of this type is not very well named, as it can be confused with the subject of the next section. A better name would be indeterminacy principle.
Epistemic uncertainty: information deficit
We started with the strongest and also strangest form of uncertainty. The second is the every day type encountered when dealing with incomplete information. In contrast to the previous type, this uncertainty is a property of our state knowledge, not a property of nature itself. So when we ask, for example, what caused the dinosaur extinction, we are referring to some fact about reality, whether or not we have or will have access to it. Or if playing poker we wonder if we have the best hand, we are referring to an unknown but existing fact, the set of all hands dealt.

Boltzmann’s tombstone with the entropy equation.
Uncertainty as incomplete information is central to fields like information theory, probability and thermodynamics where it is given a formal and quantitative treatment. The technical term is entropy, and it’s measured in bits. We say a description has high entropy if there is a lot of information missing from it. If we ask whether a fair coin will land heads or tails we are missing 1 bit of information. If we ask what number will come out from throwing a fair 8 sided die, we are missing 3 bits. The result of the die throw has more possible results, and therefore higher uncertainty about it than the coin flip result. So it has more bits of entropy. We sum up this type of uncertainty as:
The information exists, but we do not know it.
Before finishing a small clarification. If you were expecting the concept of randomness to appear when talking about coin flips and die rolls here’s the reason why it did not. In this section I have restricted the discussion to classical physics, where phenomena are deterministic although we may not know all the initial conditions. The combination of determinism + unknown initial conditions is what underlies the use of randomness in the macroscopic world. This type of randomness is sometimes called subjective randomness to distinguish it from intrinsic randomness, which is basically another term for ontological uncertainty of the first section.

A deterministic coin flipping machine
The third type..
And now to the interesting bit. Let’s say I tell you that I have all the information about something, but I still don’t know everything about it. Sounds contradictory right? Here’s an example to illustrate this kind of situation.
- All men are mortal
- Socrates is a man
If now somebody tells you that
3. Socrates is mortal.
Are they giving you any information? Hopefully it seems to you like they told you something you already knew. Does that mean you had all the information before given statement 3? Put differently, does statement 3 contain any information not present in 1,2?

One of the 24 valid syllogism types
Consider another example.
- x = 1051
- y = 3067
- x * y = 3223417
In this case statement 3 tells us something we probably didn’t know. But does statement 3 contain information not present int 1,2? We can use definitions from information theory to offer one answer. Define three random variables (for convenience in some arbitrary range a-b)
x ∈ {a-b}, y ∈ {a-b}, x*y {…}
We can calculate the conditional entropy according to the standard equation

which in our case gives
H(x*y | x, y) = 0
The conditional entropy of x*y given x and y is zero. This is just a technical way to say that given statements 1 and 2, statement 3 contains no extra information: whatever 3 tells us was already contained in 1,2. Once x and y are fixed, x*y follows necessarily. This brings us back to the beginning of the post
We could say that uncertainty is lack of knowledge or lack of information. As we’ll see these two ideas are not equivalent and do not cover all cases.
It should be apparent now that these two ideas are different. We have here cases where we have all the information about something (x, y), and yet we do not know everything about it (x*y).
Logical uncertainty: computation deficit
The step that bridges having all the information with having all the knowledge has a name: computation. Deducing (computing) the conclusion from the premises in the Socrates syllogism does not add any information. Neither does computing x*y from x and y. But computation can tell us things we did not know even though the information was there all along.

We are uncertain about the blanks, even though we have all the necessary information to fill them.
In this context, computing is a process that extracts consequences present implicitly in information. The difference between deducing the conclusion of a simple syllogism, and multiplying two large numbers is a difference in degree, not a difference in kind. However, there is a clear difference in that without sufficient computation, we will remain uncertain about things that are in a sense already there. At the upper end we have cases like Fermat’s last theorem, about which mathematicians had been uncertain for 350 years. We finish with this summary of logical uncertainty:
The information exists, we have all of it, but there are logical consequences we don’t know.

Pierre de Fermat
Cryptography: secrecy and uncertainty
Cryptography (from Greek κρυπτός kryptós, “hidden, secret”; and γράφειν graphein, “writing”) is the practice and study of techniques for secure communication in the presence of third parties called adversaries
The important word here is secret, which should remind of us uncertainty. Saying that we want a message to remain secret with respect to an adversary is equivalent to saying that we want this adversary to be uncertain about the message content. Although our first intuition would point in the direction of epistemic uncertainty, the fact is that in practice this is not usually the case.
Let’s look at an example with the Caesar cipher, named after Julius Caesar, who used it ~2000 years go. The Caesar replaces each letter in the message with another letter obtained by shifting the alphabet a fixed number of places. This number of places plays the role of encryption key. For example, with a shift of +3
abcdefghijklmnopqrstuvwxyz defghijklmnopqrstuvwxyzabc
Let’s encrypt a message using this +3 key:
cryptography is based on uncertainty fubswrjudskb lv edvhg rq xqfhuwdlqwb
We hope that if our adversary gets hold of the encrypted message he/she will not learn its secret, whereas our intended recipient, knowing the +3 shift key just needs to apply the reverse procedure (-3 shift) to recover it. When analyzing ciphers it is assumed that our adversary will capture our messages and also will know the procedure, if not the key (in this case +3) used to encrypt. Using these assumptions, let’s imagine we are the adversary and capture this encrypted message:
govv nyxo iye rkfo pyexn dro combod
We want to know the secret, but we don’t know the secret key shift value. But then we realize that the alphabet has 26 characters, and therefore there are only 25 possible shifts, a shift of 26 leaves the message unchanged. So how about trying all the keys and seeing what happens:
FNUU MXWN HXD QJEN OXDWM CQN BNLANC EMTT LWVM GWC PIDM NWCVL BPM AMKZMB DLSS KVUL FVB OHCL MVBUK AOL ZLJYLA CKRR JUTK EUA NGBK LUATJ ZNK YKIXKZ BJQQ ITSJ DTZ MFAJ KTZSI YMJ XJHWJY AIPP HSRI CSY LEZI JSYRH XLI WIGVIX ZHOO GRQH BRX KDYH IRXQG WKH VHFUHW YGNN FQPG AQW JCXG HQWPF VJG UGETGV XFMM EPOF ZPV IBWF GPVOE UIF TFDSFU <strong>WELL DONE YOU HAVE FOUND THE SECRET</strong> VDKK CNMD XNT GZUD ENTMC SGD RDBQDS UCJJ BMLC WMS FYTC DMSLB RFC QCAPCR TBII ALKB VLR EXSB CLRKA QEB PBZOBQ SAHH ZKJA UKQ DWRA BKQJZ PDA OAYNAP RZGG YJIZ TJP CVQZ AJPIY OCZ NZXMZO QYFF XIHY SIO BUPY ZIOHX NBY MYWLYN PXEE WHGX RHN ATOX YHNGW MAX LXVKXM OWDD VGFW QGM ZSNW XGMFV LZW KWUJWL NVCC UFEV PFL YRMV WFLEU KYV JVTIVK MUBB TEDU OEK XQLU VEKDT JXU IUSHUJ LTAA SDCT NDJ WPKT UDJCS IWT HTRGTI KSZZ RCBS MCI VOJS TCIBR HVS GSQFSH JRYY QBAR LBH UNIR SBHAQ GUR FRPERG IQXX PAZQ KAG TMHQ RAGZP FTQ EQODQF HPWW OZYP JZF SLGP QZFYO ESP DPNCPE
We found that the secret was revealed when trying a key shift of +10. Note how we were able to pick out the correct message because none of the other attempts gave meaningful results. This happens because the space of possible keys is so small that only one of them decrypts to a possible message. In technical terms, the key space and message space[2] are small enough compared to the length of the message that only one key will decrypt. The following equation[3] states this in terms of uncertainty:

The left part of the expression, H(Key | Ciphertext), tells us how much uncertainty about the key remains once we have obtained the encrypted message. Note the term S(c) which represents how many keys decrypt a meaningful message. As we saw above, S(c) = 1, which yields
H(K | C) = ∑ P(c) * log2 (1) = ∑ P(c) * 0 = 0
In words, there is no uncertainty about the key, and therefore the secret message, once we know the encrypted message[4]. Of course, when we initially captured this
govv nyxo iye rkfo pyexn dro combod
we did not know the secret, but we had all the information necessary to reveal it. We were only logically uncertain about the secret and needed computation, not information, to find it out.

Alberti’s cipher disk (1470)
Although we have seen this only for the simple Caesar cipher, it turns out that except for special cases, many ciphers have this property given a large enough message to encrypt. In public key ciphers, like those used in many secure voting systems, this is the case irrespective of message size. So we can say that practical cryptography is based around logical uncertainty, since our adversaries have enough information to obtain the secret. But as we saw previously, there are different degrees of logical uncertainty. Cryptography depends on this uncertainty being “strong” enough to protect secrets.
Talking about degrees of logical uncertainty leads us to computational complexity.
Computational complexity and logical uncertainty
Just as entropy measures epistemic uncertainty, computational complexity can be said to measure logical uncertainty. In probability theory we study how much information one needs to remove epistemic uncertainty. Computational complexity studies how much computation one needs to remove logical uncertainty. We saw that deducing the conclusion of the Socrates syllogism was easy, but multiplying two large numbers was harder. Complexity looks at how hard these problems are relative to each other. So if we are looking for the foundations of cryptography we should definitely look there.
Take for example the widely used RSA public key cryptosystem. This scheme is based (among other things) on the computational difficulty of factoring large numbers. We can represent this situation with two statements, for example
- X=1522605027922533360535618378132637429718068114961380688657908494580122963258952897654000350692006139
- X=3797522793694367392280887275544562785456553663 199*40094690950920881030683735292761468389214899724061
Statement 2 (the factors) is entailed by statement 1, but obtaining 2 from 1 requires significant computational resources. In a real world case, an adversary that captures a message encrypted under the RSA scheme will require such an amount of computation to reveal its content, that this possibility is labeled infeasible. Let’s be a bit more precise than that. This means that an adversary, using the fastest known algorithm for the task, will require thousands of years of computing on a modern pc.
If the last statement didn’t trigger alarm bells, perhaps I should emphasize the words “known algorithm”. We know that with known algorithms the task is infeasible, but what if a faster algorithm is found? You would expect complexity theory would have an answer to that hypothetical situation. The simple fact of the matter is that it doesn’t.
In complexity theory, problems for which efficient algorithms exist are put into a class called P. Although no efficient algorithm is known for integer factorization, whether it is in P or not is an open problem[5]. In other words, we are logically uncertain about whether factorization is in P or not!

Several complexity classes
If we assume that integer factorization is not in P then a message encrypted with RSA is secure. So in order to guarantee an adversary’s logical uncertainty about secret messages, cryptographic techniques rely on assumptions that are themselves the object of logical uncertainty at the computational complexity level! Not the kind of thing you want to find when looking for foundations.
The bottom line
It’s really not that bad though. If you think carefully about it, what matters is not just whether factorization and other problems are in P or not, but whether adversaries will find the corresponding efficient algorithms. The condition that factorization is in P and that the efficient algorithms are secretly found by adversaries is much stronger than the first requirement on its own. More importantly, the second condition seems to be one we can find partial evidence for.
Whether or not evidence can be found for a logical statement is a controversial subject. Does the fact that no one has proved that factorization is in P count as evidence that it is not in P? Some say yes and some say no. But it seems less controversial to say that the fact that no algorithm has been found counts as evidence for the possibility that we (as a species with given cognitive and scientific level of advancement) will not find it in the near future.

A quantum subroutine
The bottom line for the foundations of cryptography is a question of both logical and epistemic uncertainty. On one hand, computational complexity questions belong in the realm of logic, and empirical evidence for this seems conceptually shaky. But the practical aspects of cryptography not only depend on complexity questions, but also on our ability to solve them. Another point along these lines is that computational complexity tells us about difficulty for algorithms given certain computational primitives. But the question of what primitives we have access to when building computing devices is a question of physics (as quantum computing illustrates). This means we can justify or question confidence in the security of cryptography through empirical evidence about the physical world. Today, it is the combination of results from computational complexity together with empirical evidence about the world that form the ultimate foundations of cryptography.
References
[1] Along the x, y, or z axes
[2] Without going into details, the message space is smaller than the set of all combinations of letters given that most of these combinations are meaningless. Meaningful messages are redundantly encoded.
[3] http://www14.in.tum.de/konferenzen/Jass05/courses/1/papers/gruber_paper.pdf
[4] The equation refers to the general case, but we can still use it to illustrate a particular case.
[5] To be precise, it’s that and the more general question of whether P=NP.